En este caso se trató el estatus CONFIDENCIAL como eliminado, al igual que en la sección anterior.
Se construyen dos modelos de clasificación — Árbol de Decisión y Random Forest — para predecir la variable objetivo ESTATUS_VICTIMA a partir de las demás variables del dataset.
Objetivo: Predecir ESTATUS_VICTIMA (DESAPARECIDA / NO LOCALIZADA).
Preparación del dataset
Se parte del mismo dataset limpio usado en la sección anterior, aplicando las mismas transformaciones: eliminación de registros CONFIDENCIAL, discretización de edad en grupos de riesgo y clasificación del año de desaparición por sexenio.
Carga y limpieza del dataset
import pandas as pdimport numpy as npdf = pd.read_csv("data_secretariado.csv")# Eliminar registros con CONFIDENCIAL en columnas clavecols_clave = ["SEXO", "ESTATUS_VICTIMA", "ENTIDAD","FECHA_NACIMIENTO", "FECHA_DESAPARICION"]for col in cols_clave: df = df[df[col] !="CONFIDENCIAL"]df = df[df["SEXO"] !="INDETERMINADO"]# Parsear fechas df["FECHA_NACIMIENTO"] = pd.to_datetime(df["FECHA_NACIMIENTO"], errors="coerce")df["FECHA_DESAPARICION"] = pd.to_datetime(df["FECHA_DESAPARICION"], errors="coerce")df = df.dropna(subset=["FECHA_NACIMIENTO", "FECHA_DESAPARICION"])# Calcular edad al momento de la desaparición df["EDAD"] = ((df["FECHA_DESAPARICION"] - df["FECHA_NACIMIENTO"]) .dt.days //365).astype(int)df = df[df["EDAD"].between(0, 120)]# Discretizar edad en grupos de riesgo bins = [-1, 11, 17, 29, 59, 120]labels = ["0-11", "12-17", "18-29", "30-59", "60+"]df["GRUPO_EDAD"] = pd.cut(df["EDAD"], bins=bins, labels=labels)# Extraer mes y sexenio de la fecha de desaparición meses = {1:"Enero", 2:"Febrero", 3:"Marzo", 4:"Abril", 5:"Mayo",6:"Junio", 7:"Julio", 8:"Agosto", 9:"Septiembre",10:"Octubre", 11:"Noviembre", 12:"Diciembre"}df["MES_DESAPARICION"] = df["FECHA_DESAPARICION"].dt.month.map(meses)anio = df["FECHA_DESAPARICION"].dt.yeardf["SEXENIO"] = pd.cut( anio, bins=[1999, 2006, 2012, 2018, 2024, 2030], labels=["Fox", "Calderón", "Peña Nieto", "AMLO", "Sheinbaum"])# Quedarse solo con las dos clases objetivo df = df[df["ESTATUS_VICTIMA"].isin(["DESAPARECIDA", "NO LOCALIZADA"])]print(f"Registros tras limpieza: {len(df):,}")print()print(df["ESTATUS_VICTIMA"].value_counts())
Registros tras limpieza: 50,867
ESTATUS_VICTIMA
DESAPARECIDA 48116
NO LOCALIZADA 2751
Name: count, dtype: int64
Consideraciones sobre el desbalance de clases
Distribución de la variable objetivo
conteo = df["ESTATUS_VICTIMA"].value_counts()pct = df["ESTATUS_VICTIMA"].value_counts(normalize=True) *100print("Distribución de ESTATUS_VICTIMA:")for clase in conteo.index:print(f" {clase:<20}{conteo[clase]:>7,} ({pct[clase]:.1f}%)")
Distribución de ESTATUS_VICTIMA:
DESAPARECIDA 48,116 (94.6%)
NO LOCALIZADA 2,751 (5.4%)
El dataset presenta un fuerte desbalance: la clase DESAPARECIDA representa aproximadamente el 94% de los registros válidos. Un modelo que predijera siempre DESAPARECIDA tendría una accuracy altísima sin aprender nada útil. Por tal razón se optó por no usar este modelo.
Balancea precisión y recall para ambas clases por igual, penalizando el desempeño pobre en la clase minoritaria (NO LOCALIZADA). Es la métrica principal.
Recall por clase
\(\frac{TP}{TP + FN}\)
En desapariciones es crítico no pasar por alto a una víctima NO LOCALIZADA. Recall alto en esa clase significa que el modelo identifica correctamente esos casos.
Precision por clase
\(\frac{TP}{TP + FP}\)
Indica cuántas predicciones positivas son correctas, evitando falsas alarmas.
Accuracy
\(\frac{TP + TN}{Total}\)
Como mencionamos anteriormente esta métrica no se usará por el desvalance.
Relación con el mundo real: En búsqueda de personas, un falso negativo — clasificar como DESAPARECIDA a alguien NO LOCALIZADA — puede implicar que el caso no reciba la atención urgente que requiere. Por eso el recall en NO LOCALIZADA tiene mayor peso práctico que la accuracy global.
Codificación de variables y división train/test
Preparación de features y división 80/20
from sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import LabelEncoder# Features y variable objetivo features = ["SEXO", "GRUPO_EDAD", "ENTIDAD", "MES_DESAPARICION", "SEXENIO"]target ="ESTATUS_VICTIMA"df_model = df[features + [target]].dropna()# Codificación de variables categóricasdf_enc = df_model.copy()encoders = {}for col in features: le = LabelEncoder() df_enc[col] = le.fit_transform(df_enc[col].astype(str)) encoders[col] = lele_target = LabelEncoder()df_enc[target] = le_target.fit_transform(df_enc[target])X = df_enc[features]y = df_enc[target]# División 80/20 estratificada X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42, stratify=y)print(f"Entrenamiento : {len(X_train):,} registros")print(f"Prueba : {len(X_test):,} registros")print(f"Features : {features}")print(f"Clases : {le_target.classes_}")
Se usa una división 80/20 estratificada (stratify=y) para garantizar que la proporción entre clases se mantenga igual en entrenamiento y prueba, lo cual es esencial con datasets desbalanceados.
Entrenamiento de los modelos
Árbol de Decisión
Árbol de Decisión
from sklearn.tree import DecisionTreeClassifierfrom sklearn.metrics import classification_report, accuracy_scoredt = DecisionTreeClassifier( max_depth=8, # limita profundidad para evitar sobreajuste min_samples_leaf=50, # cada hoja requiere mínimo 50 muestras class_weight="balanced", # compensa el desbalance de clases random_state=42)dt.fit(X_train, y_train)y_pred_dt = dt.predict(X_test)print("─── Árbol de Decisión ───")print(f"Accuracy : {accuracy_score(y_test, y_pred_dt):.4f}\n")print(classification_report(y_test, y_pred_dt, target_names=le_target.classes_))
─── Árbol de Decisión ───
Accuracy : 0.7792
precision recall f1-score support
DESAPARECIDA 0.99 0.78 0.87 9565
NO LOCALIZADA 0.17 0.82 0.29 548
accuracy 0.78 10113
macro avg 0.58 0.80 0.58 10113
weighted avg 0.94 0.78 0.84 10113
Random Forest
Random Forest
from sklearn.ensemble import RandomForestClassifierrf = RandomForestClassifier( n_estimators=100, # 100 árboles en el bosque max_depth=10, min_samples_leaf=30, class_weight="balanced", # compensa el desbalance de clases n_jobs=-1, # usa todos los núcleos disponibles random_state=42)rf.fit(X_train, y_train)y_pred_rf = rf.predict(X_test)print("─── Random Forest ───")print(f"Accuracy : {accuracy_score(y_test, y_pred_rf):.4f}\n")print(classification_report(y_test, y_pred_rf, target_names=le_target.classes_))
─── Random Forest ───
Accuracy : 0.8115
precision recall f1-score support
DESAPARECIDA 0.98 0.81 0.89 9565
NO LOCALIZADA 0.19 0.78 0.31 548
accuracy 0.81 10113
macro avg 0.59 0.80 0.60 10113
weighted avg 0.94 0.81 0.86 10113
Comparativa entre modelos
Tabla comparativa de métricas
from sklearn.metrics import f1_score, precision_score, recall_scoremodelos = {"Árbol de Decisión": y_pred_dt,"Random Forest": y_pred_rf,}idx_no_loc =list(le_target.classes_).index("NO LOCALIZADA")print(f"{'Modelo':<22}{'Accuracy':>10}{'F1 macro':>10} "f"{'Recall NO LOC':>15}{'Prec NO LOC':>13}")print("─"*74)for nombre, y_pred in modelos.items(): acc = accuracy_score(y_test, y_pred) f1 = f1_score(y_test, y_pred, average="macro") rec = recall_score(y_test, y_pred, average=None)[idx_no_loc] prec = precision_score(y_test, y_pred, average=None)[idx_no_loc]print(f"{nombre:<22}{acc:>10.4f}{f1:>10.4f}{rec:>15.4f}{prec:>13.4f}")
Modelo Accuracy F1 macro Recall NO LOC Prec NO LOC
──────────────────────────────────────────────────────────────────────────
Árbol de Decisión 0.7792 0.5777 0.8157 0.1733
Random Forest 0.8115 0.6004 0.7810 0.1933
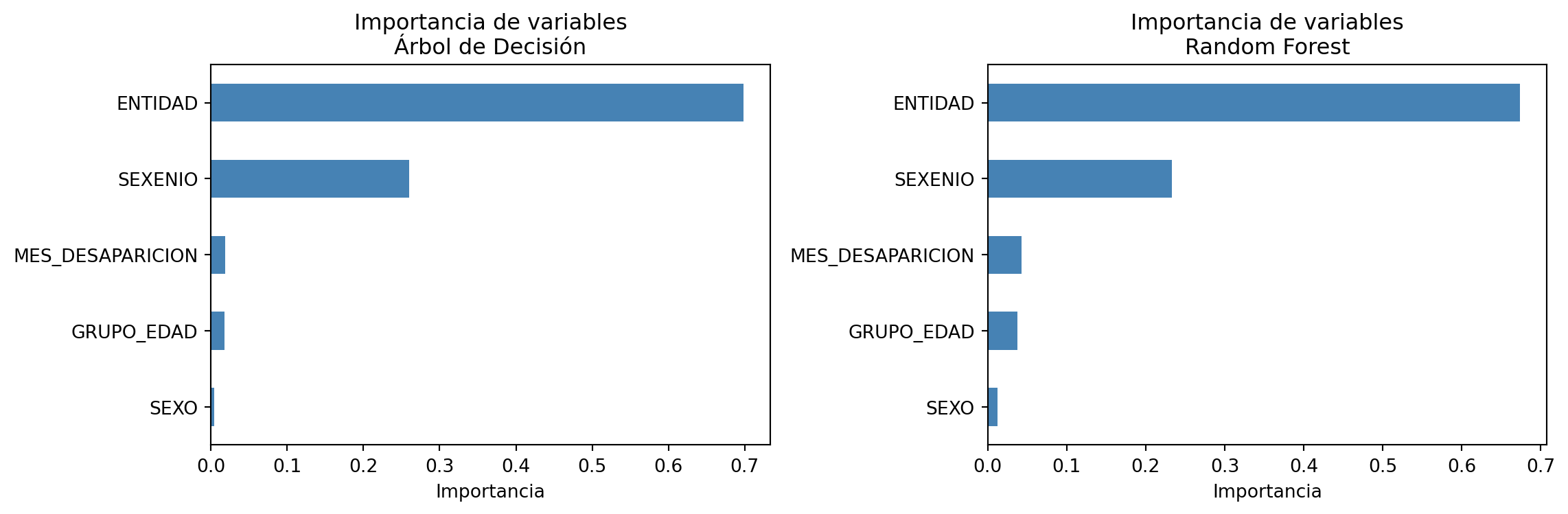
Variables más relevantes
Importancia de variables — Árbol de Decisión y Random Forest
Ambos modelos coinciden en que ENTIDAD, GRUPO_EDAD y SEXO son las variables con mayor poder predictivo, lo cual es consistente con los patrones encontrados en la sección de reglas de asociación.
Discusión: ¿patrones reales o sesgos?
Los modelos capturan patrones estadísticamente reales dentro del dataset disponible, con lo anterior podemos decir que:
Sesgo de registro: El 37% de los registros originales son CONFIDENCIAL y fueron excluidos. Si la confidencialidad no es aleatoria, el modelo aprende patrones sesgados hacia las entidades con mayor transparencia en el registro.
Desbalance de clases: Aunque se usó class_weight="balanced" para compensarlo, el modelo sigue teniendo más información sobre DESAPARECIDA que sobre NO LOCALIZADA. El recall en la clase minoritaria refleja este límite estructural.
Cobertura temporal desigual: Los sexenios con menos registros (Fox, Calderón) tienen menor representación en el entrenamiento, por lo que el modelo puede no generalizar bien a patrones históricos.
Variables ausentes: El dataset no incluye variables socioeconómicas, contexto de violencia regional ni tipo de desaparición, que podrían ser predictoras importantes del estatus final de la víctima.
En conclusión, los modelos reflejan en parte el fenómeno real y en parte las limitaciones del sistema de registro. Deben usarse como herramienta exploratoria, no como sistema de decisión definitivo.